Machine Learning

Louis
Comment optimiser les performances des modèles de Machine Learning avec du MLOps ?

Dans cet article, nous explorons l’application des pratiques du MLOps pour optimiser les performances des modèles de Machine Learning et assurer leur fiabilité en production.
Dans le monde de l’Intelligence Artificielle et du Machine Learning, de nombreuses organisations sont confrontées au défi de passer d’un simple prototype à la mise en production d’un modèle. L’industrialisation d’un modèle de Machine Learning pose en effet plusieurs problématiques ou défis techniques, tels que l’évolution des données disponibles, le réentrainement et le déploiement automatisé des modèles, etc. Dans cet article, nous aborderons comment les pratiques du MLOps peuvent être utilisées pour optimiser les performances des modèles de Machine Learning et garantir leur fiabilité au cours du temps dans un environnement de production.
Mettre en place une approche MLOps permet de surveiller et d’anticiper la dégradation des performances des modèles de Machine Learning au fil du temps. Une fois qu’un modèle a été entraîné et déployé, il est essentiel de suivre ses performances pour s’assurer qu’il continue de produire des résultats précis et fiables. Sans une surveillance appropriée, les performances d’un modèle peuvent se dégrader en raison de changements dans les données d’entrée, dans les données cibles ou d’autres facteurs externes.
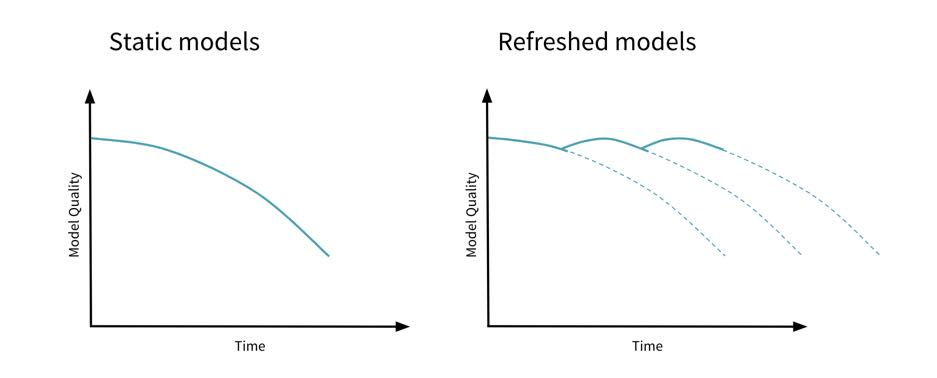
La réponse à notre problème réside dans l’application des pratiques du MLOps, en particulier dans la surveillance des modèles. Il existe différentes méthodes pour surveiller les performances du modèle et détecter les dégradations éventuelles :
Qualité des données : Il est essentiel de surveiller la qualité des données utilisées pour l’entraînement et l’inférence du modèle. Cela comprend la vérification du volume des données, l’intégrité des colonnes, la cohérence des types de données, etc. Tout écart par rapport aux attentes peut être un indicateur d’un problème potentiel.
Détection des données aberrantes (outliers) : Afin d’améliorer la fiabilité de notre modèle et de ses prédictions, nous ajoutons un modèle de détection des anomalies dont l’objectif est d’évaluer les données d’entrée de notre modèle de prédiction. Parfois, des données étranges peuvent apparaître, très différentes de l’ensemble d’apprentissage, et la prédiction a plus de chances d’être erronée.
Drift des données : Le “drift” (dérive) des données se produit lorsque les nouvelles données d’entrée évoluent ou diffèrent de celles sur lesquelles le modèle a été entraîné. Il est important de détecter ces drifts pour éviter la dégradation des performances de prédiction des modèles. Des méthodes statistiques, telles que la divergence de Jensen-Shannon et la métrique de Wasserstein, peuvent être utilisées pour mesurer ce drift des données.
Drift conceptuel : Le drift conceptuel (concept drift en anglais) se produit lorsque la relation entre les données d’entrée et les données cibles (celles que l’on essaye de prédire) change. Cela peut se produire en raison de changements dans l’environnement extérieur ou les processus sous-jacents. Bien qu’il n’y ait pas de méthode statistique directe pour évaluer le drift conceptuel, il peut être surveillé en comparant les drifts des données d’entrée et des données cibles.
Évaluation des performances du modèle : Il est essentiel de collecter des données sur les prédictions du modèle et de les comparer à la réalité lorsque celle-ci est disponible. Cela permet de mesurer l’exactitude et la cohérence du modèle dans des conditions réelles.
Estimation des performances du modèle : L’estimation des performances du modèle sans connaissance des données cibles réelles peut être réalisée en utilisant des méthodes telles que CBPE, de l’anglais Confidence-based Performance Estimation. Cela permet d’avoir une idée des performances attendues du modèle avant que les données réelles ne soient disponibles.
Interprétabilité : Cette partie ne surveille pas directement la performance des modèles, mais l’interprétabilité est un sujet clé du MLOps et peut être utile pour comprendre l’origine et l’impact d’un drift des données/conceptuel.
NannyML est une librairie Python open-source permettant facilement de monitorer des modèles de Machine Learning. NannyML est conçue pour détecter les défaillances silencieuses des modèles : estimer les performances du modèle après le déploiement, détecter des drifts dans les données et surveiller les performances une fois que les données cibles sont disponibles.
Grâce à cette librairie on peut notamment surveiller le drift des données de manière univariée. C’est-à-dire surveiller un drift de la distribution de chaque variable indépendamment. Voici schématiquement comment ce drift est monitoré :
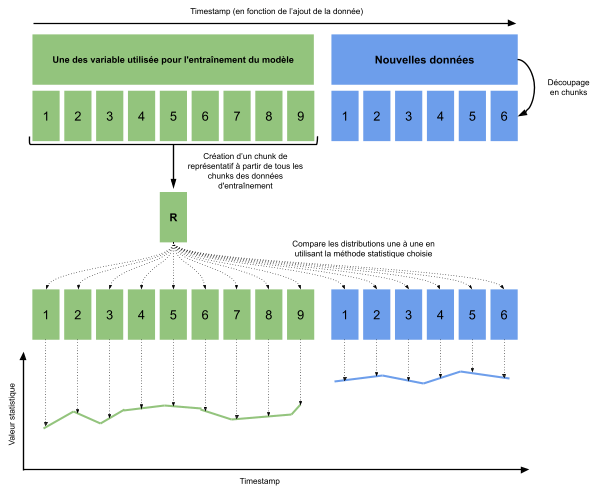
Il est aussi possible de surveiller le drift des données de manière multivariée. C’est-à-dire surveiller un drift de la distribution de toutes les variables en même temps. Voici schématiquement comment ce drift est monitoré :
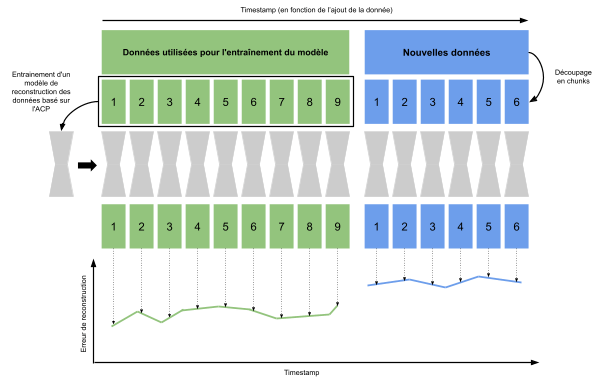
En conclusion, les pratiques du MLOps jouent un rôle essentiel dans l’optimisation des performances des modèles de Machine Learning. Grâce à des outils tels que NannyML et la mise en place de tableaux de bord de surveillance, il est possible de surveiller en continu et en temps réel les performances des modèles, d’anticiper les dégradations et de détecter les drifts de données. Cela garantit la fiabilité et la pertinence des prédictions des modèles dans un environnement de production. Bien que la mise en place de ces techniques nécessite une expertise technique et une coordination étroite avec les experts métier, les avantages en termes de qualité des déploiements futurs de modèles valent la peine d’investir dans les pratiques de MLOps.
Lorem ipsum dolor sit amet consectetur. Ipsum penatibus viverra feugiat amet varius pharetra porta risus lectus. Turpis enim massa non tincidunt in faucibus.









