Pandas, Pyspark, Koalas - Quelle librairie choisir pour son projet Data Science ?

Cet article compare trois bibliothèques Python en analyse de données. Pandas convient aux volumes limités, PySpark gère de grandes quantités grâce à la parallélisation, et Koalas facilite la transition de Pandas à Spark.
Les projets de data science requièrent des outils spécifiques selon la phase du projet. Cet article présente un aperçu de 3 librairies python souvent utilisées en analyse de données et confronte leur utilisation.Pandas, la base…
Si vous avez déjà fait de l’analyse de données sur Python, vous n’avez pas pu passer à côté de la librairie Pandas !
En effet, cette librairie est l’une des plus utilisées pour la manipulation de données. C’est devenu un incontournable de par sa facilité de prise en main, sa praticité et l’ensemble des fonctionnalités disponibles pour la manipulation de données.
L’objet de base de cette librairie que sont les DataFrames (tableaux, voir ci-dessous) en font un outil très intuitif car cet objet est très facile à appréhender quand on travaille avec des données structurées. Pandas permet de charger ou écrire très facilement de la donnée provenant d’un fichier csv, Excel ou d’une base de données SQL. De plus, Pandas contient une multitude de fonctions optimisées permettant de manipuler cette donnée tabulaire. En effet, les parties critiques de code sont parfois codées en Python ou C pour gagner en rapidité d’exécution.
Ces différents avantages en font le choix par excellence pour le traitement de données sur Python quand on travaille sur une volumétrie de données limitée.
L’utilisation d’un framework comme Spark intervient généralement après la phase de preuve de concept, ou PoC. Pour rappel, une PoC est un projet très court terme visant à débroussailler un sujet de data science. La PoC sert à prouver la faisabilité et la valeur ajoutée de l’approche sur un périmètre réduit (avec une quantité raisonnable de données). Dans ce cadre là, les data scientists ont donc tout intérêt à utiliser leurs outils favoris afin d’avancer rapidement.
Lorsque dans un second temps, on veut industrialiser cette PoC, c’est-à-dire l’appliquer à une échelle plus grande, on se retrouve généralement confronté à des problèmes de performance. En effet, il se peut que la volumétrie de données explose quand on passe au périmètre complet par rapport à l’échantillon de départ, ce qui peut créer de grosses latences dans l’exécution des calculs voire le non-aboutissement de certains.
Pour remédier à cela, il sera nécessaire d’utiliser des frameworks permettant de paralléliser les calculs, d’où l’utilisation de Spark avec son interface en python PySpark. Un des avantages de pySpark est aussi la distinction entre ”lazy operation” et les actions. En effet, Spark ne va exécuter le code et donc lancer des calculs uniquement quand c’est nécessaire.
Voilà un exemple de code en PySpark en comparaison avec Pandas, on notera que le langage diffère beaucoup et qu’une adaptation est nécessaire pour passer de Pandas a PySpark :
import pandas as pd
df = pd.DataFrame({‘col1’: [1, 2], ‘col2’: [3, 4], ‘col3’: [5, 6]})
df[‘col4’] = df.col1 * df.col1
df = spark.read.option(“inferSchema”, “true”).option(“comment”, True).csv(“my_data.csv”)
df = df.toDF(‘col1’, ‘col2’, ‘col3’)
df = df.withColumn(‘col4’, df.col1*df.col1)
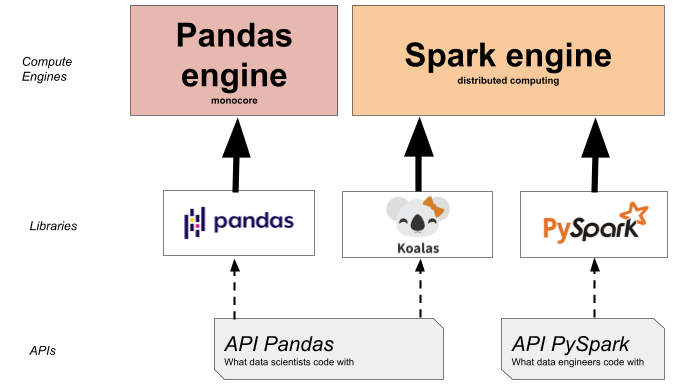
Koalas est une librairie très récente (fin 2019) qui vise à écrire des programmes Spark avec la syntaxe de Pandas. Elle permet d’unifier la production du code d’expérimentation et d’industrialisation sous le même outil, tout en bénéficiant de la flexibilité de Pandas et de la performance distribuée de Spark.
C’est donc une solution intermédiaire tout à fait pertinente qui sera particulièrement adaptée aux Data Scientists qui maîtrisent déjà Pandas et qui souhaitent aller vers des volumétries de données plus importantes en restant avec des outils familiers, et donc sans avoir à se former entièrement à un nouveau langage. A noter en revanche que toutes les fonctionnalités de Pandas ne sont pas encore disponibles dans la librairie Koalas.

Par exemple, en reprenant le même code que précédemment sur Koalas :
import databricks.koalas as ks
df = ks.DataFrame({‘col1’: [1, 2], ‘col2’: [3, 4], ‘col3’: [5, 6]})
df[‘col4’] = df.col1 * df.col1
On remarque bien la similitude avec l’écriture du code sous Pandas. Ici, seul le nom de la librairie a changé mais le code est resté exactement le même qu’avec Pandas.
Des subtilités existent toujours entre les deux environnements et PySpark reste le framework de référence en Big Data de la communauté de Data Engineers. Ces derniers sont souvent déjà familiers du langage Spark et n’auront que très peu d’intérêt à en changer au bénéfice de Koalas. De plus Koalas est une augmentation de l’API DataFrame de Spark pour se rapprocher de Pandas, ce qui fait que le langage de fond reste bien Spark. Si, par exemple, il y a un besoin de performance supplémentaire, il peut être nécessaire de revenir à Spark sans surcouche. De plus Spark est prévu pour être facilement intégrable avec tout un tas d’autres outils étant donné sa popularité.
Dans le graphe ci-dessous (produit par Databricks), on peut voir que pySpark a tout de même des performances supérieures à Koalas, même si Koalas est déjà très performant par rapport à Pandas. Il est aussi intéressant de noter que pour des petits jeux de données, Pandas est plus performant (dû aux opérations d’initialisation et de transfert de données des solutions distribuées) et donc plus adapté.

Koalas peut aussi être utilisé comme approche pour apprendre Spark progressivement, mais dans tous les cas il est nécessaire de pratiquer dans l’environnement Spark.
Il est évidemment possible de passer d’un langage à un autre grâce à certaines fonctions comme to_pandas() mais il est recommandé de ne les utiliser le moins possible car ce sont des opérations très coûteuses étant donné que cela impacte le format de stockage de la donnée.
Nos data scientists utilisent (Py)Spark et Koalas pour traiter des calculs sur de gros volumes de données. Si vous souhaitez en apprendre davantage sur cette technologie et l’implémenter dans vos projets de big data, contactez-nous !
Lorem ipsum dolor sit amet consectetur. Ipsum penatibus viverra feugiat amet varius pharetra porta risus lectus. Turpis enim massa non tincidunt in faucibus.









