DVC : l’outil clé pour la gestion des données en ML

Le contrôle de version facilite le travail indépendant des développeurs sur un projet. DVC (data version control) étend ce concept aux données en permettant une gestion efficace. Cet article explore DVC, définissant son rôle en data science et expliquant son utilisation.
Lors du développement de projets de data science et de machine learning, il est essentiel de disposer d’outils permettant de gérer le versionnage des données. Le versionnage des données permet de suivre les modifications apportées aux ensembles de données, d’enregistrer les différentes versions et de collaborer efficacement avec d’autres membres de l’équipe. Cela garantit la reproductibilité des expériences, facilite la comparaison des résultats et permet de revenir à des versions précédentes si nécessaire.
Dans cette section, nous présenterons un panorama de quelques-uns des principaux outils de contrôle de version de données, en mettant en évidence leurs fonctionnalités et leurs approches spécifiques. Parmi ces outils, nous trouverons :

DVC est un outil open-source conçu spécifiquement pour le versionnage de données. Il offre une approche simple et légère pour gérer les versions de données, avec une intégration transparente avec Git. DVC se distingue par sa capacité à maintenir la flexibilité et la portabilité des données.

Git LFS est une extension de Git qui permet de gérer et de versionner de gros fichiers de données. Il est couramment utilisé dans les projets de développement logiciel pour suivre les fichiers binaires, mais peut également être utilisé pour versionner des données. Cependant, Git LFS peut présenter des limitations en termes de performances et de gestion de fichiers volumineux.

Pachyderm est une plateforme open-source qui combine le versionnage de données avec des pipelines de traitement de données. Il permet de gérer des ensembles de données de grande taille et de suivre les modifications apportées aux données. Pachyderm offre des fonctionnalités avancées telles que la répétabilité des pipelines et la gestion des versions de données, mais il peut nécessiter une courbe d’apprentissage plus longue et une configuration plus complexe.

MLflow est une plateforme open-source développée par Databricks pour la gestion du cycle de vie des modèles de machine learning. Bien que sa principale fonction soit le suivi et le déploiement de modèles, MLflow dispose également de fonctionnalités de versionnage des données. Cependant, il est plus axé sur la gestion des expériences et des modèles que sur le versionnage spécifique des données.

Neptune.ai est une plateforme collaborative pour les projets de data science. Elle offre des fonctionnalités de suivi des expériences, de gestion des versions de code et de données, ainsi que des capacités de collaboration en équipe. Neptune.ai se concentre sur la visualisation des expériences et la gestion des métadonnées, offrant ainsi une vue complète du processus de développement de modèles.
Vous avez une idée du panorama des outils de contrôle de version de données les plus couramment utilisés dans les projets de data science et de machine learning. Chacun de ces outils offre ses propres fonctionnalités et approches pour répondre aux besoins spécifiques de gestion et de collaboration autour des données.
Dans la suite de cet article, nous nous concentrerons plus en détail sur DVC. Nous explorerons ses fonctionnalités avancées, son intégration avec Git, ainsi que ses avantages spécifiques pour le versionnage de données dans les projets de data science et de machine learning. Vous découvrirez comment DVC peut améliorer la gestion de vos ensembles de données, simplifier la collaboration au sein de votre équipe et vous aider à maintenir une traçabilité rigoureuse des modifications apportées aux données.
DVC est une bibliothèque Python open source qui offre des fonctionnalités avancées pour la gestion des versions des données dans les projets de data science et d’apprentissage automatique. DVC peut être installé facilement à l’aide d’outils couramment utilisés tels que conda ou pip, ce qui le rend accessible à un large éventail d’utilisateurs.
Une des particularités de DVC est son extension gratuite et open source pour l’éditeur de code Visual Studio Code (VS Code). Cette extension fournit un tableau de bord qui permet de visualiser les différentes versions des données, des modèles et des expériences d’apprentissage automatique. Cette fonctionnalité facilite la navigation et la compréhension de l’historique des versions, ainsi que la comparaison des résultats obtenus à différentes étapes du projet.
En utilisant DVC, les data scientists et les développeurs peuvent facilement gérer les ensembles de données, les modèles et les configurations, tout en maintenant la reproductibilité des expériences et la traçabilité des résultats. DVC s’intègre de manière transparente avec les outils de contrôle de version tels que Git, ce qui facilite la collaboration entre les membres de l’équipe et permet de partager facilement les ensembles de données et les modèles entraînés.
En résumé, DVC est une bibliothèque Python puissante, accompagnée d’une extension pour VS Code, qui offre des fonctionnalités avancées pour la gestion des versions des données dans les projets de science des données et d’apprentissage automatique.
DVC a été conçu pour répondre à plusieurs objectifs essentiels dans la gestion des versions des données, favorisant ainsi la collaboration efficace dans les projets de science des données et d’apprentissage automatique. Les principaux objectifs de DVC sont les suivants :
DVC est spécifiquement conçu pour gérer des fichiers volumineux, tels que les ensembles de données et les modèles d’apprentissage automatique, ainsi que leurs métriques associées. Il stocke ces données dans un dépôt sécurisé et distribué, assurant leur intégrité et leur disponibilité pour les utilisateurs. Ainsi, les utilisateurs peuvent travailler en toute confiance, sachant que leurs données sont protégées et qu’ils peuvent y accéder facilement pour leurs besoins d’analyse et de collaboration
Lorsqu’il s’agit de projets de développement, il est devenu courant et même essentiel de versionner le code pour bénéficier des avantages évidents que cela apporte à la communauté logicielle. Le suivi de chaque modification du code permet aux développeurs de naviguer dans le temps, de comparer les versions antérieures et de résoudre les problèmes tout en minimisant les perturbations pour l’équipe. Après tout, le code est un actif précieux qui doit être protégé à tout prix !
Le même principe s’applique aux données. Voici quatre raisons pour lesquelles vous devriez utiliser un outil de contrôle de version pour les données :
Les modèles d’apprentissage automatique sont généralement développés en combinant du code, des données et des fichiers de configuration, ce qui peut rendre la reproduction des résultats complexe. DVC résout ce problème en versionnant les données et en suivant les dépendances, ce qui permet de reproduire les mêmes résultats sur différentes machines ou à différents moments.
DVC facilite la collaboration au sein des équipes travaillant sur des projets d’apprentissage automatique. En versionnant les données, il devient plus facile de partager le travail et de s’assurer que tous les membres travaillent avec les mêmes entrées et sorties. Il simplifie également l’examen des modifications et permet de suivre les contributeurs.
DVC vous aide à suivre les expériences et les résultats qu’elles produisent. En versionnant les données, vous pouvez facilement voir quelles expériences ont été menées avec quelles versions du code et des données, ainsi que les résultats obtenus. Cela facilite l’itération sur les modèles et l’amélioration des performances au fil du temps.
À mesure que vos projets d’apprentissage automatique se développent, il devient de plus en plus difficile de gérer les données et le code. DVC résout ce problème en versionnant les données, ce qui facilite la gestion et la mise à l’échelle du projet à mesure qu’il grandit. De plus, il optimise l’efficacité de stockage en ne sauvegardant que les modifications apportées aux données plutôt que l’ensemble du jeu de données.
En adoptant DVC, vous bénéficierez de ces avantages, ce qui améliorera la reproductibilité, la collaboration, le suivi des expériences et la scalabilité de vos projets d’apprentissage automatique.

L’utilisation de DVC comprend plusieurs étapes clés pour le versionnage et la gestion des données. Voici comment DVC fonctionne :
Pour commencer, vous pouvez créer un fichier .dvc en utilisant la commande dvc add fichier. Ce fichier spécifie le chemin vers le répertoire qui contient la version actuelle des données. Ensuite, vous pouvez utiliser DVC pour créer un espace de stockage distant. Cela peut être un emplacement dans le cloud (AWS, GCP, Azure, Palantir Foundry, etc.) ou un serveur/répertoire séparé de votre projet. Vous pouvez créer cet espace de stockage distant en utilisant la commande dvc remote add directement depuis le terminal. Enfin, vous pouvez pousser cette version de données vers le stockage distant en utilisant la commande dvc push. Cela garantit la sécurité et la possibilité de récupération des données originales.
Lorsque vous modifiez le fichier de données d’origine, DVC met à jour automatiquement le fichier .dvc pour avoir un nouveau chemin pointant vers les données modifiées. Vous pouvez mettre à jour ce fichier en utilisant la même commande dvc add fichier. En utilisant Git, vous pouvez suivre les modifications de ce fichier .dvc et retrouver n’importe quelle version de données souhaitée en utilisant les différents messages de commit de Git.
En utilisant la commande dvc push, vous pouvez stocker les différentes versions des données dans l’espace de stockage distant. Cela vous permet de conserver un historique complet des versions précédentes des données dans cet espace. Ainsi, vous avez la possibilité de récupérer n’importe quelle version spécifique de données qui existe dans le stockage distant. Cette fonctionnalité offre une grande flexibilité et vous permet de revenir à des versions antérieures des données si nécessaire, ce qui peut être particulièrement utile lors de l’exploration des modèles ou de la comparaison des performances entre différentes versions de données. En utilisant DVC, vous avez la tranquillité d’esprit de savoir que vos données sont sécurisées, accessibles et répétables à tout moment.
Un point important à noter est que les fichiers de données eux-mêmes ne sont jamais suivis par Git. Dans les projets utilisant DVC, seuls les fichiers avec l’extension .dvc sont suivis par Git. Cela permet de gérer efficacement les fichiers volumineux de données tout en conservant la gestion des versions avec Git.
En utilisant ces étapes, DVC permet de suivre l’historique des versions des données, de les stocker de manière sécurisée et de les récupérer facilement, tout en travaillant en harmonie avec Git pour le suivi des modifications du fichier .dvc. Cela facilite la gestion des données dans les projets de science des données et d’apprentissage automatique.
Le MLOps est une méthodologie qui vise à faciliter la mise en production et la maintenance efficace des modèles d’apprentissage automatique (ML). Il s’agit d’une combinaison de pratiques, d’outils et de processus visant à automatiser et à standardiser les workflows ML, tout en garantissant la reproductibilité, la collaboration et l’évolutivité des projets ML.
L’importance d’un outil de contrôle de version des données dans le MLOps est cruciale. Les modèles ML dépendent non seulement du code, mais également des données utilisées pour les entraîner, les valider et les déployer. Un outil de contrôle de version des données tel que DVC permet de versionner et de suivre les données, de garantir la reproductibilité des expériences, de faciliter la collaboration entre les équipes, d’automatiser les pipelines de données, et d’assurer la gestion efficace des dépendances des modèles ML. Cela permet aux équipes MLOps de maintenir un contrôle rigoureux sur les données et de s’assurer de la cohérence des résultats, tout en facilitant la résolution des problèmes et le déploiement des modèles en production.
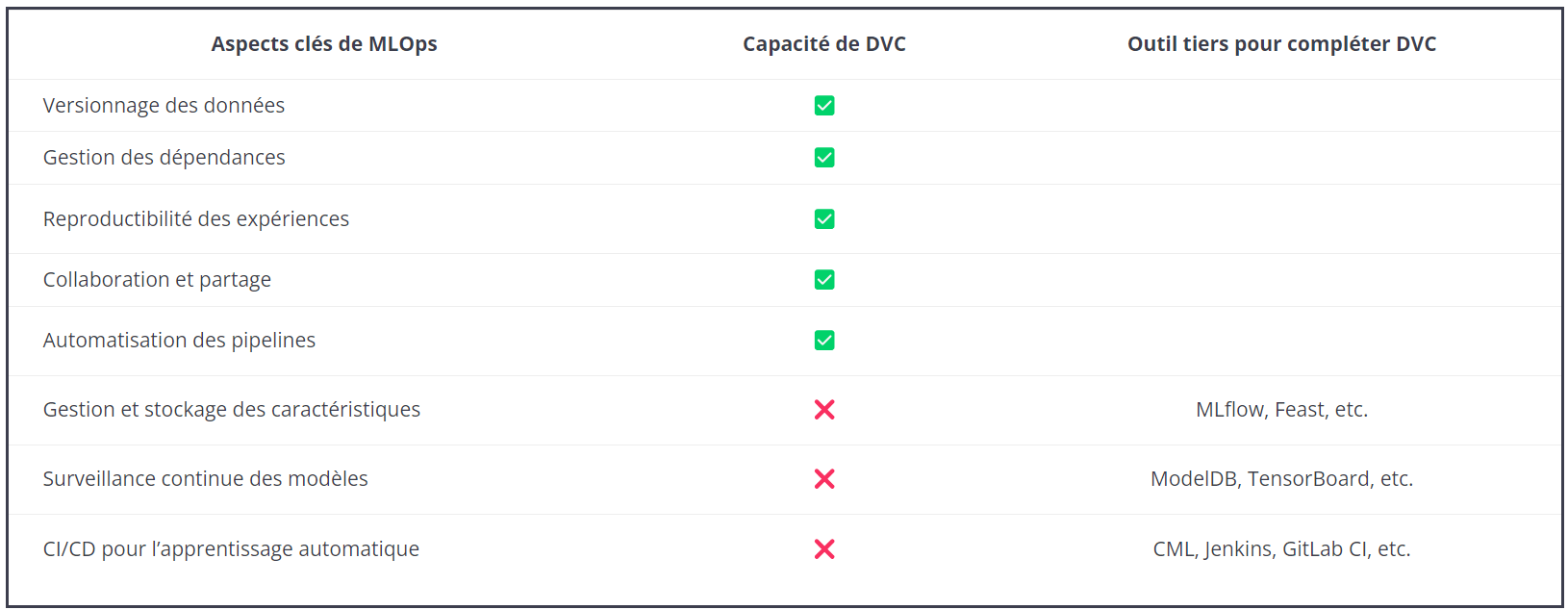
Un outil de contrôle de version des données tel que DVC joue un rôle essentiel dans la mise en place du MLOps en permettant la gestion rigoureuse des données, la reproductibilité des expériences, la collaboration entre les équipes et l’automatisation des pipelines. Bien qu’il ne réponde pas à tous les aspects du MLOps, DVC peut être complété par d’autres outils spécialisés pour répondre aux besoins spécifiques de gestion des caractéristiques, de surveillance des modèles et de CI/CD. En utilisant DVC et d’autres outils de manière synergique, les équipes MLOps peuvent améliorer l’efficacité, la qualité et la fiabilité de leurs projets ML.
DVC offre plusieurs avantages clés dans le domaine du MLOps. Il permet de versionner les données, de suivre les modifications, de restaurer des versions précédentes en cas de besoin, et de faciliter la collaboration en fournissant un moyen cohérent de gérer les entrées et les sorties des modèles. De plus, DVC s’intègre facilement avec d’autres outils de MLOps tels que MLflow, permettant ainsi une gestion plus complète du cycle de vie des modèles.
En conclusion, l’utilisation d’un outil de contrôle de version des données comme DVC est cruciale dans un environnement MLOps. Cela garantit la reproductibilité des expériences, facilite la collaboration entre les équipes, permet une gestion efficace des données et contribue à l’automatisation des processus. En intégrant DVC dans votre flux de travail MLOps, vous pouvez améliorer l’efficacité, la traçabilité et la fiabilité de vos projets de data science.
Lorem ipsum dolor sit amet consectetur. Ipsum penatibus viverra feugiat amet varius pharetra porta risus lectus. Turpis enim massa non tincidunt in faucibus.









