Comment l’augmentation de données améliore les performances en Computer Vision ?

Cet article présente « image blending », une méthode d’augmentation d’images. Il explique le mélange homogène d’images pour générer des données d’entraînement réalistes pour la détection d’objets. Une application concrète est illustrée dans la détection d’étoiles de mer sur des images de la barrière de corail.
Les modèles d’apprentissage automatique occupent une place de plus en plus importante dans la recherche et l’industrie, en raison de progrès impressionnants notamment dans des tâches jusque-là réservées à des experts humains. Pour apprendre, les modèles passent par une phase d’entraînement pour laquelle ils ont généralement besoin de données labellisées. Une règle générale est que plus on a de données disponibles, plus le modèle gagne en performance étant donné qu’il aura la possibilité de capter davantage de phénomènes (patterns) lors de son apprentissage. Ce constat est d’autant plus vrai que le problème et la donnée sont complexes.

Dans le cadre des sujets de reconnaissance d’objets, il n’est pas rare que le jeu d’apprentissage soit petit, voire inexistant. Il est en effet coûteux de labelliser manuellement de grand volume d’images, spécifiquement quand une certaine expertise est nécessaire (dans le cadre de l’imagerie médicale par exemple).
Une des méthodes les plus utilisées pour répondre à ce problème est la Data Augmentation (DA), autrement dit l’augmentation artificielle de la taille du dataset en utilisant des méthodes de manipulation d’image. Cette augmentation est classiquement réalisée en effectuant des opérations modifiant l’aspect de l’image, sans pour autant en modifier la sémantique : par exemple, en changeant la luminosité, en effectuant une rotation / un effet miroir, en changeant l’échelle, ou encore en ajoutant du bruit.

Dans cet article, nous nous intéresserons à une méthode d’augmentation plus avancée : l’image blending. L’image blending est un processus de transfert d’une image du domaine source vers le domaine cible tout en garantissant que les pixels transformés sont conformes au domaine cible pour assurer la cohérence.

L’idée est ainsi d’augmenter le nombre d’images disponibles pour l’entraînement d’un modèle de détection d’objet, en ajoutant directement l’objet cible dans des backgrounds différents. On obtient ainsi très facilement des images labellisées : sachant où l’objet a été introduit, on peut créer en même temps la bounding box (qui sert de label) correspondante.
Plus précisément, nous nous intéresserons au Gradient Domain Blending, qui permet d’effectuer un mélange homogène des images. L’intérêt est de générer des images sans frontière entre le fond et l’objet ajouté, afin qu’elles soient suffisamment réalistes pour être utiles à l’entraînement d’un modèle de détection.
Le principe, inspiré de ces travaux, consiste à résoudre l’équation de Poisson associée au gradient de l’image sur la zone, définie par un masque, où le mélange doit se faire. Le masque permet de mieux préciser où se situe l’objet d’intérêt sur l’image, et de définir un dégradé pour fluidifier la transition entre les deux images.
L’algorithme prend ainsi quatres éléments en entrée:
On obtient en sortie une nouvelle image, déjà labellisée, contenant l’objet d’intérêt. Ainsi, en répétant le processus sur un nombre suffisamment important d’images de fond, on peut créer une nouvelle base de données prête à être utilisée pour l’entraînement d’un algorithme de détection d’objets comme YOLO.
Ci-contre, un exemple d’objet d’intérêt et du masque correspondant : la zone blanche défini peu ou prou la position de l’objet sur l’image.
L’exemple d’application que nous allons étudier provient d’un dataset mis à disposition pour une compétition Kaggle proposant la détection d’une famille d’étoile de mer (Crowns of Thorns Starfish, ou CoTS) sur des images vidéos de la grande barrière de corail Australienne.
Le dataset à disposition contient 23.000 images, dont environ 5.000 incluant les objets à détecter. L’idée est d’utiliser les 18.000 images de fonds marins ne contenant pas d’informations utiles comme base pour cette méthode d’augmentation.
La première étape consiste à construire un dataset, dans notre cas d’une cinquantaine d’entrées, d’objets à ajouter aux fonds afin de simuler une diversité de cas. Le plus gros du travail manuel est à cette étape, pour collecter les images et définir les masques correspondants. Ce dataset est ensuite augmenté à l’aide des techniques classiques (miroir, rotations, contraste …) afin d’obtenir une base d’objet la plus variée possible.
Mais générer des images en positionnant aléatoirement l’objet sur un fond ne suffit pas : afin d’obtenir un modèle utilisable dans des cas réels, il faut que les images générées soient des exemples plausibles en réalité. Imaginons par exemple que l’on cherche à développer un algorithme de détection de vélo sur route. Si on utilise cette méthode pour augmenter un dataset existant en insérant des images de vélo sur des images de fond contenant une route, on veut insérer les objets ‘vélo’ sur la route et non au sommet d’un arbre en bordure par exemple.
Ainsi, la seconde étape consiste à analyser les images réelles du dataset afin de s’en inspirer. On s’intéresse notamment à la taille des objets à détecter, et à leur répartition spatiale sur les vraies images.
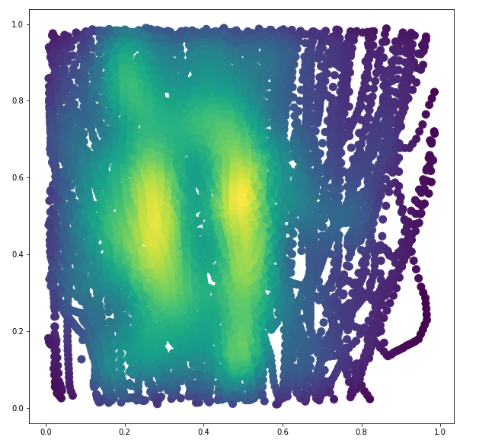
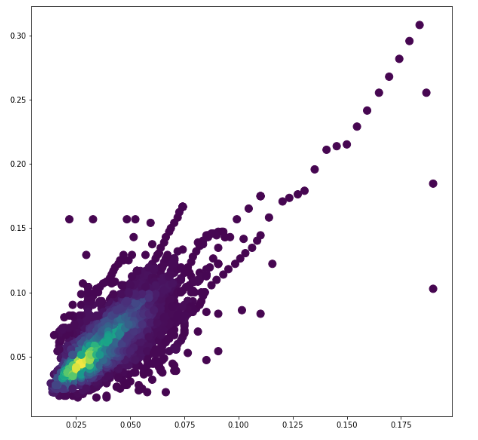
Les répartitions ainsi obtenues nous permettront de construire des images dont la diversité se rapproche le plus possible de la réalité.
Enfin, on passe à la génération des nouvelles images :
Ci-dessous, 2 exemples avant/après d’images augmentées avec le label correspondant, qu’un modèle de détection pourrait utiliser comme ensemble d’entraînement.




Même après avoir analysé les images réelles pour comprendre leur contexte, il n’est pas impossible de générer des images aberrantes. Par exemple, dans les images d’exemple ci-avant, on pourrait introduire par inadvertance des objets à détecter dans des zones où il est impossible d’avoir des objets réels (comme les zones où il n’y a que de l’eau). Sans vérification supplémentaire, introduire ces données irréalistes dans le jeu d’entraînement risquerait de faire apprendre de mauvais patterns au modèle.
Une solution consiste à commencer par entraîner un premier modèle sur le dataset non augmenté. On peut ensuite, sur un principe similaire à celui des GANs, utiliser ce modèle pour détecter les objets présents sur nos nouvelles images : si le modèle basé sur de la donnée réelle arrive à repérer les nouveaux “faux” objets, on peut inférer qu’ils sont suffisamment réalistes pour être utilisable comme base d’entraînement.
En conclusion, la data augmentation est un composant indispensable du processus d’amélioration des modèles prédictifs. Plus particulièrement, l’image blending permet d’aller plus loin dans des domaines où peu de données labellisées sont disponibles. Il ne faut cependant pas tomber dans le piège d’augmenter sans comprendre le contexte de la donnée et le but du modèle de d’apprentissage automatique, afin de ne pas introduire de données aberrantes dans notre modèle.
Vous avez une idée de cas d’utilisation impliquant de l’analyse automatique d’images mais vous estimez avoir un jeu de données d’entraînement trop restreint ? Contactez-nous pour identifier dans quelle mesure l’augmentation de données pourrait être utile.
Lorem ipsum dolor sit amet consectetur. Ipsum penatibus viverra feugiat amet varius pharetra porta risus lectus. Turpis enim massa non tincidunt in faucibus.









