Interprétabilité et explicabilité des modèles de Machine Learning

Cet article présente SHAP, une méthode d’interprétation mesurant l’impact des variables sur les prédictions. Illustrée avec les données du Titanic et un algorithme XGBoost, SHAP offre une explication locale mais présente des inconvénients en termes de temps de calcul et de simulation aléatoire. Des alternatives, comme LIME, sont également disponibles.
Le Machine Learning tient maintenant une grande place dans les processus décisionnels des entreprises car son degré de précision a augmenté de manière accrue ces dernières décennies.
Toutefois, l’opacité des algorithmes de Machine Learning (ML) et de Deep Learning soulèvent de nos jours des questions d’ordre éthique et juridique. Le besoin de confiance et de transparence est ainsi très présent et très prisé.
Pour ces raisons, l’interprétabilité et l’explicabilité des modèles font dorénavant partie intégrantes du métier des Data Scientists qui doivent s’efforcer de convaincre leurs clients et utilisateurs de l’acceptabilité du raisonnement de leur modèle. Heureusement pour eux de nombreuses méthodes existent maintenant pour faciliter ce travail qui même pour un technophile peut être laborieux.
Tout d’abord, avant de rentrer dans les détails, commençons par définir ces termes pour bien distinguer leur différence :
Nous allons maintenant nous arrêter plus précisément sur une méthode d’interprétabilité dont nous allons expliciter le fonctionnement ainsi que ses points positifs et négatifs : SHAP.
La méthode SHAP est basée sur la théorie des jeux. Pour faire simple, elle permet de mesurer l’impact sur la prédiction d’ajouter une variable (toutes choses égales par ailleurs) grâce à des permutations de toutes les options possibles.
Par exemple, si on veut estimer l’effet du genre d’une personne sur une prédiction, on va tester sur chaque combinaison possible des autres variables la différence des prédictions entre genre = Homme et genre = Femme. Visuellement, on peut voir ci-dessous l’impact de « l’interdiction des chats » sur le prix d’un appartement.
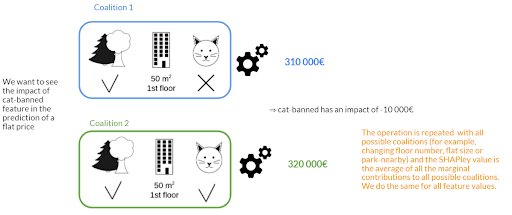
En sortie, nous obtenons une SHAPley valeur qui représente l’impact d’une variable sur la prédiction. Dans l’exemple ci-dessus, une SHAPley valeur haute indiquera que la valeur de la variable tend à faire augmenter le prix de l’appartement.
Nous allons maintenant vous montrer comment SHAP nous permet concrètement d’interpréter les résultats d’un algorithme XGBoost.
Cet exemple portera sur les données Titanic (https://www.kaggle.com/c/titanic/data), pour lesquelles le but est de prédire les passagers survivants en utilisant des données les concernant avec par exemple : Sex_female=genre, Pclass=classe dans le bâteau, Fare=prix du ticket, Age=âge… La valeur à prédire correspond à la variable Survived qui prend la valeur 1 pour la survie du passager.
Le graphique ci-dessous montre l’ensemble des SHAPley valeurs par observation et par observation. La couleur des points correspond à la valeur de la variable et le positionnement horizontal des points correspond à la SHAPley valeur.
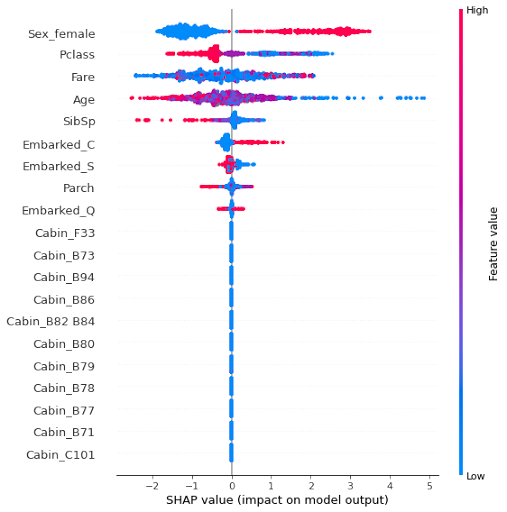
On peut voir par exemple, que pour la variable Sex_female, si la valeur est 0 (point bleu, le passager est un homme), alors les SHAPley valeurs sont négatives (situées sur la gauche) donc en défaveur de la prédiction Survived (1).
Au contraire, si la valeur est 1 (point rouge, le passager est une femme), les SHAPley valeurs sont positives (situées sur la droite) donc en faveur de la prédiction Survived (1).
Conclusion : on a plus de chance de survivre au naufrage du Titanic si on est une femme !
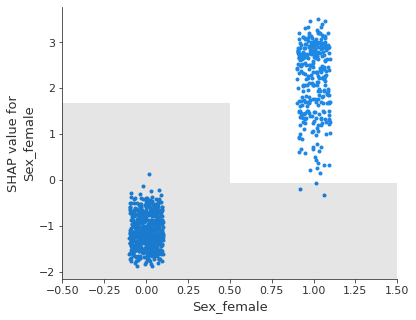
On retrouve ces résultats dans le graphe ci-dessous où l’on voit clairement les deux modalités et leur impact significatif dans la prédiction.
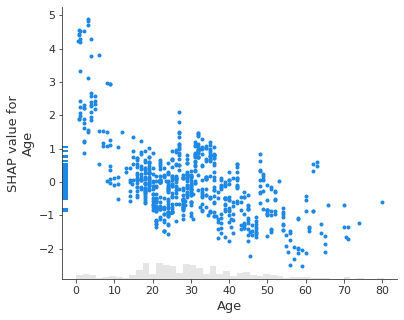
Sur le graphe suivant, on voit clairement que les passagers âgés de moins de 10 ans avaient le plus de chances de survivre puisque c’est lorsque l’axe des x est inférieur à 10, que les SHAPley valeurs sont les plus hautes donc les plus en faveur de la survie (puisqu’elles font augmenter la valeur de la prédiction)
Il est aussi possible de croiser les variables. Par exemple ici, on veut voir l’impact sur la prédiction de la variable PClass et Sex_female. En ordonnées on a les SHAPley valeurs, en abscisse la variable PClass et en couleur la variable Sex_female. Ce que l’on voit c’est que la classe 1 a le plus de chances de survie, ensuite vient la 2ème et enfin la 3ème classe. En plus de cela, dans les premières et deuxièmes classes, on voit que les femmes ont le plus de chance de survie (en rouge) car leurs SHAPley valeurs sont au-dessus de celles des hommes. Ce qui est inversé en 3ème classe (!)

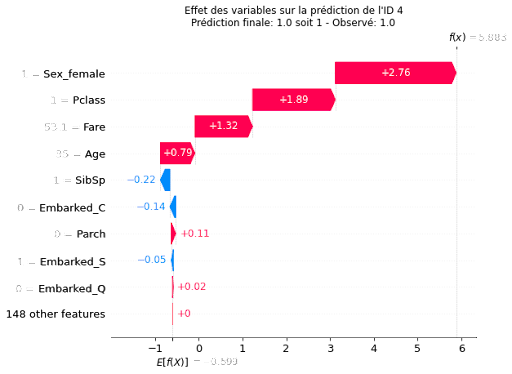
Il est également possible d’expliquer quels ont été les drivers pour amener à la prédiction finale pour un individu en particulier. Il s’agit donc d’une explication locale et non globale.
Dans le graphe ci-dessous, on peut voir l’impact de chacune des caractéristiques de l’individu choisi et comment ces caractéristiques impactent la prédiction. En bleu les caractéristiques ayant une SHAPley valeur négative donc en défaveur de la survie et en rouge les caractéristiques ayant une SHAPley valeur positive donc en faveur de la survie. Ces SHAPley valeurs sont additives. Pour l’individu ci-dessous, on voit que le fait qu’elle soit une femme a fait augmenter sa prédiction de survie, qui a été également confortée par le fait qu’elle soit en première classe.
Pour conclure sur la méthode SHAP, nous allons dresser un bilan des points positifs et négatifs de cette méthode :
Avantages SHAP : L’avantage majeur de la méthode SHAP est qu’elle garantit que la prédiction est équitablement distribuée parmi les variables, c’est donc une méthode robuste (basé sur de la théorie solide) et fiable si l’on souhaite faire un audit de modèle par exemple. De plus, les graphiques sont propres et lisibles rendant leur utilisation parfaite face à un client non-expert.
Inconvénients SHAP : Par contre, son désavantage principal est le temps de calcul qui augmente de manière exponentielle avec le nombre de variables disponibles (2^k coalitions possibles). Cela peut être compensé par de l’échantillonnage mais cela augmente alors la variance. Les explications déduites de SHAP sont toujours sous condition de « sachant le set restant de variables », c’est-à-dire que la méthode utilise systématiquement toutes les variables. Le fait de ne pas avoir de modèle en output, à contrario de LIME par exemple, fait que pour une nouvelle observation, il faut relancer l’explication. Et enfin le fait que certaines valeurs soient simulées aléatoirement peut générer des points non réalistes: par exemple âge = 15 et majeur = Oui, car les simulations sont aléatoires et ne prennent pas en compte les corrélations entre les variables.
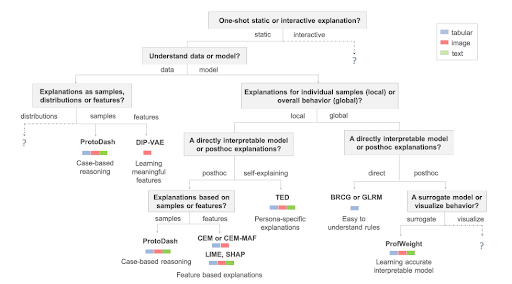
SHAP n’est pas l’unique méthode qui existe dans ce domaine. Comme mentionnée précédemment LIME est également une méthode qui se base sur les features pour expliquer les résultats du modèle. Par contre, contrairement à la méthode SHAP, elle consiste à re-créer un modèle linéaire grâce à des observations simulées autour du point d’intérêt. Comme vous pouvez le voir sur le graphique ci-dessous d’autres méthodes peuvent être utilisées dépendamment de la structure de votre projet.
Lorem ipsum dolor sit amet consectetur. Ipsum penatibus viverra feugiat amet varius pharetra porta risus lectus. Turpis enim massa non tincidunt in faucibus.









